Last updated on 4 months ago
基础篇 变量类型 rune uint8
1 2 3 4 5 6 7 8 9 10 11 12 func traversalString () "pprof.cn博客" for i := 0 ; i < len (s); i++ { "%v(%c) " , s[i], s[i])for _, r := range s { "%v(%c) " , r, r)
结果是
1 2 112 (p ) 112 (p ) 114 (r ) 111 (o ) 102 (f ) 46 (. 99 (c ) 110 (n ) 229 (å) 141 () 154 () 229 (å) 174 (®) 162 (¢)112 (p ) 112 (p ) 114 (r ) 111 (o ) 102 (f ) 46 (. 99 (c ) 110 (n ) 21338 (博) 23458 (客)
可以uint8是单独取出字符串中每个元素的ascii码进行处理,超出ascii码的范围就做不到了,像这种中文的就打印不出来
修改字符串 要修改一个字符串,首先需要把字符串转换成数组类型,然后再进行修改
数组赋值 1 2 3 4 5 6 7 8 9 10 11 12 var c [5 ]int {2 :40 ,4 :50 }for _,i := range c{println (i)
%s打印字符串
切片 var s1 []int
s3:=make([]int,0)
结构体 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 package main import ("fmt" type student struct {string int func main () var p1 student"yblue" 18 "%#v\n%v\n" , p1, p1)"usr0" "%#v\n%v\n" , p2, p2)"root" ,"%#v\n%v\n" , p3, p3)
还有可能有别的创建结构体的方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 type student struct {string int func main () make (map [string ]*student) "pprof.cn" , age: 18 },"测试" , age: 23 },"博客" , age: 28 },for _, stu := range stus {for k, v := range m {"=>" , v.name)
方法和接收 Go语言中的方法(Method)是一种作用于特定类型变量的函数。这种特定类型变量叫做接收者(Receiver)。
自定义函数跟方法的组成区别 自定义函数是func newPerson(name, city string, age int8) *person {} func后直接跟自定义的函数名,而方法是要先声明接收者变量和接收者类型
1 2 3 4 func (接收者变量 接收者类型)
举个栗子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 type Person struct {string int8 func NewPerson (name string , age int8 ) return &Person{func (p Person) "%s的梦想是学好Go语言!\n" , p.name)func main () "测试" , 25 )
指针类型的接收者 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 package mainimport "fmt" func (p *Person) int ){ type Person struct {int string func main () 18 ,"小明" ,20 )
接口 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 package mainimport "fmt" type Person interface {type Student struct {string int func (stu Student) func main () "yblue" ,18 ,var s1 Person = s
结构体与JSON序列化 JSON键值对是用来保存JS对象的一种方式,键/值对组合中的键名写在前面并用双引号””包裹,使用冒号:分隔,然后紧接着值;多个键值之间使用英文,分隔。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 type Student struct {int string string type Class struct {string func main () "101" ,make ([]*Student, 0 , 200 ),for i := 0 ; i < 10 ; i++ {"stu%02d" , i),"男" ,append (c.Students, stu)if err != nil {"json marshal failed" )return "json:%s\n" , data)`{"Title":"101","Students":[{"ID":0,"Gender":"男","Name":"stu00"},{"ID":1,"Gender":"男","Name":"stu01"},{"ID":2,"Gender":"男","Name":"stu02"},{"ID":3,"Gender":"男","Name":"stu03"},{"ID":4,"Gender":"男","Name":"stu04"},{"ID":5,"Gender":"男","Name":"stu05"},{"ID":6,"Gender":"男","Name":"stu06"},{"ID":7,"Gender":"男","Name":"stu07"},{"ID":8,"Gender":"男","Name":"stu08"},{"ID":9,"Gender":"男","Name":"stu09"}]}` byte (str), c1)if err != nil {"json unmarshal failed!" )return "%#v\n" , c1)
结构体,字段,方法,类型大统一 理解结构体、字段、方法和类型之间的关系是理解 Go 语言的重要基础。让我用一个简单的例子来说明这些概念之间的关系。
假设我们想创建一个程序来表示矩形,并能够计算其面积。我们可以使用结构体、字段、方法和类型来完成这个任务。
首先,我们定义一个矩形的结构体:
1 2 3 4 type Rectangle struct {float64 float64
在上面的代码中,我们创建了一个名为 Rectangle 的结构体,它有两个字段:Width 和 Height,分别表示矩形的宽度和高度。
接下来,我们可以为这个结构体定义一个方法来计算矩形的面积:
1 2 3 func (r Rectangle) float64 {return r.Width * r.Height
在上面的代码中,我们为 Rectangle 结构体定义了一个名为 Area 的方法。这个方法接收一个 Rectangle 类型的接收者(receiver),并返回一个 float64 类型的面积值。方法可以访问接收者结构体的字段,这里我们用 r.Width 和 r.Height 计算了面积。
现在,我们可以创建一个 Rectangle 类型的对象,并使用它的 Area 方法来计算面积:
1 2 3 4 5 func main () 5.0 , Height: 3.0 }"矩形的面积是: %f\n" , area)
在上面的 main 函数中,我们创建了一个 Rectangle 类型的对象 rect,并调用了它的 Area 方法来计算面积。最终,我们打印出了矩形的面积。
这个例子涵盖了以下概念:
结构体 (Rectangle):用于组织相关字段的数据结构。
网络编程 socket 看不懂搞不明白,过
tcp网络编程 创立客户端(client) 一个TCP客户端进行TCP通信的流程如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 package mainimport ("bufio" "fmt" "log" "net" "os" "strings" func main () "tcp" , ":12345" )if err != nil {defer conn.Close()for {'\n' )"\n\r" )if strings.ToUpper(ipinfo) == "Q" {return byte (ipinfo)) if err != nil {512 ]byte {} if err != nil {string (buf[:n]))
建立服务端(server) TCP服务端程序的处理流程:
1.监听端口
2.接收客户端请求建立链接
3.创建goroutine处理链接
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 package mainimport ("bufio" "fmt" "log" "net" func process (conn net.Conn) defer conn.Close()for {512 ]byte {}if err != nil {string (rd[:n]))"你已成功发送,数据为:%s" , string (rd[:n]))byte (recv))func main () "tcp" , ":12345" )if err != nil {for {if err != nil {go process(conn)
UDP网络编程 就是把前面的tcp换成udp,但教程还给了udp专门的socket的函数,但是感觉没什么大用,碰到再学吧
tcp黏包 就是数据发送过多,让数据包重合了
http编程 服务端 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 package mainimport ("fmt" "net/http" func main () "/index" , myHandler)"127.0.0.1:1234" , nil )func myHandler (w http.ResponseWriter, r *http.Request) defer r.Body.Close()":连接成功" )"method:" , r.Method)"url:" , r.URL.Path)"header:" , r.Header)"body:" , r.Body)byte ("这是服务器发来的消息" ))
客户端 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 package mainimport ("fmt" "io" "log" "net/http" func main () "http://127.0.0.1:1234/index" )if err != nil {defer resp.Body.Close()make ([]byte , 1024 )for {if err != nil && err != io.EOF {else {"读取完成" )string (buf[:n]))
websocket编程(聊天室) https://github.com/taosu0216/go_stu/tree/main/Internet_coding/web_socket
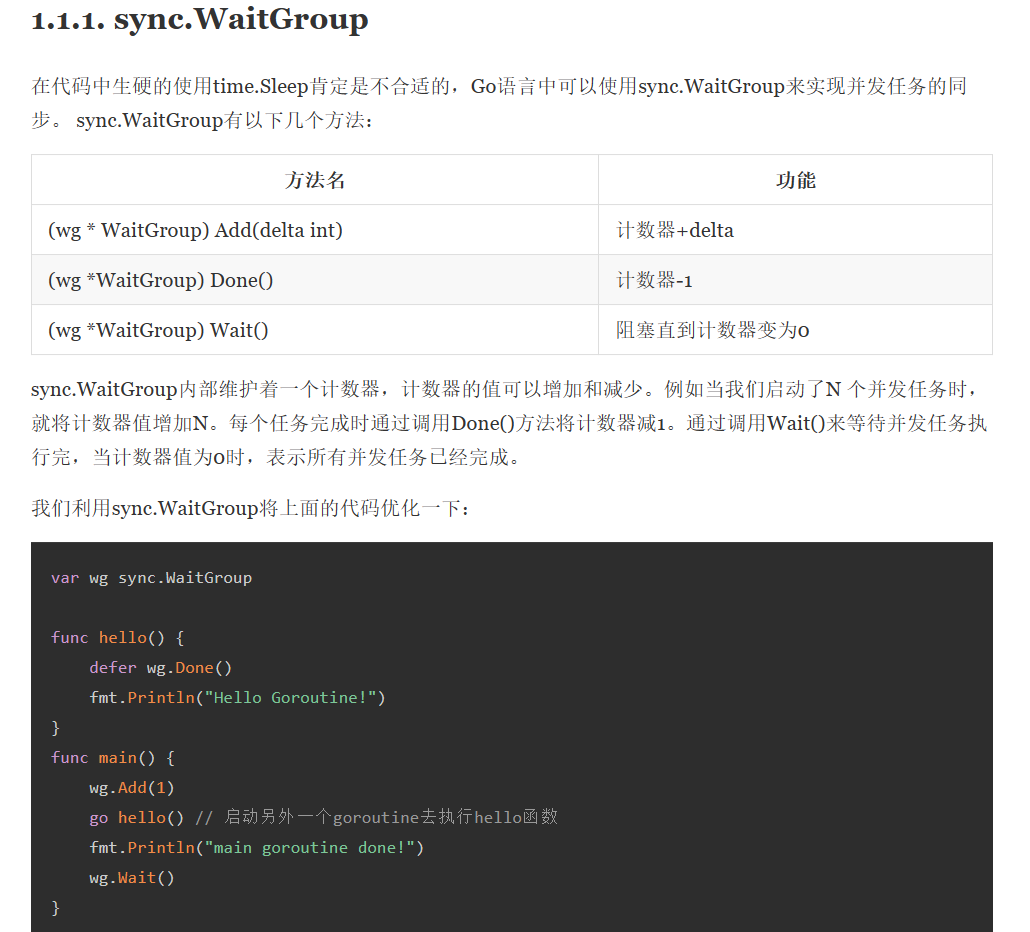
并发 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 package mainimport ("fmt" "sync" var wg sync.WaitGroupfunc hello (i int ) defer wg.Done()"Goroutine " , i, " 号开始执行" )func main () for i := 1 ; i <= 10 ; i++ {1 )go hello(i)go hello(i + 10 )
channel 通道可以关闭,但关闭通道不是必须的
channel分为有缓冲和无缓冲
判断channel是否关闭 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 package mainimport ("fmt" func main () make (chan int , 20 )make (chan int , 20 )go func () for i := 0 ; i <= 10 ; i++ {close (ch1)go func () for {if !ok {break defer close (ch2)for i := range ch2 {
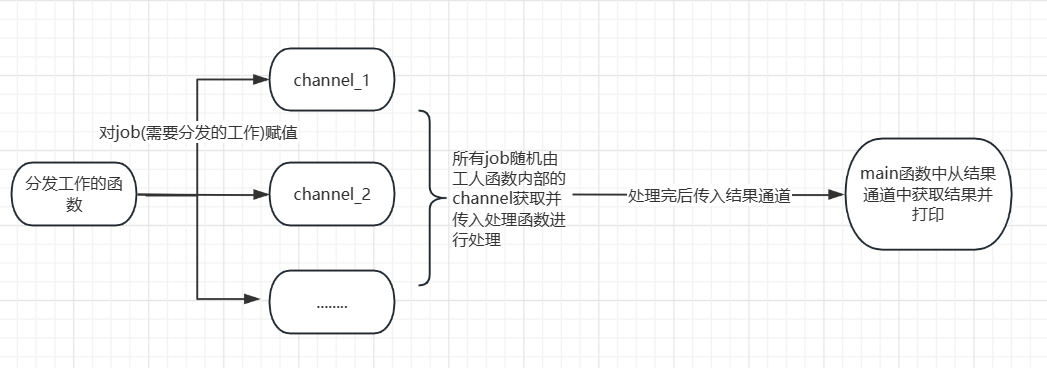
worker pool(Goroutine池)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 package mainimport ("fmt" "math/rand" type Result struct {int type Job struct {int int func main () make (chan *Job, 128 )make (chan *Result, 128 )64 , send_channel, result_channel)go func (result_c chan *Result) for result := range result_c {"第" , result.job.Id+1 , "个job,它的随机值是:" , result.job.Random_number, "是它的结果是:" , result.sum)defer close (send_channel)defer close (result_channel)for i := 0 ; i < 1000 ; i++ {func worker_pool (num int , sc chan *Job, rc chan *Result) for i := 0 ; i < num; i++ {go func (sc chan *Job, rc chan *Result) for job := range sc {0 for r_num != 0 {10 10
定时器 timer 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 type Timer struct {chan Timetype Time struct {func Now () func NewTimer (d Duration)
正式程序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 package mainimport ("fmt" "time" func main () "%v" , t)for {"时间到" )2 * time.Second)"过去了2秒" )go func () "收到时间" )2 * time.Second)for t.Stop() {"已关闭" )3 * time.Second)1 * time.Second)
ticker 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 package mainimport ("fmt" "time" func main () 1 * time.Second)0 go func () for {if i == 5 {for {
timer和ticker的区别
使用Ticker的主要场景包括:
Ticker的工作流程:
select _,ok := <- channel
1 2 3 4 5 6 7 8 select {case <-chan1:case chan2 <- 1 :default :
如果多个通道同时就绪,则只选择一个随机执行,剩下的数据都被丢弃,所以写的时候要注意好逻辑,否则可能会丢失数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 package mainimport ("fmt" func main () make (chan int , 1 )make (chan string , 1 )go func () 1 go func () "hello" select {case value := <-int_chan:"int:" , value)case value := <-string_chan:"string:" , value)"main结束" )
sync
并发安全和锁 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 var x int64 var wg sync.WaitGroupfunc add () for i := 0 ; i < 5000 ; i++ {1 func main () 2 )go add()go add()
Mutex, mutual exclusion,即互斥锁的英文
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 package mainimport ("fmt" "sync" "time" var x int64 var wg sync.WaitGroupvar lock sync.Mutexfunc add () for i := 0 ; i < 200 ; i++ {1 func main () 2 )go add()go add()
读写锁 互斥锁是所有操作都被禁止,但是大部分应用场景是读多写少,互斥锁使用时不能读不能写,会堵塞进程降低性能,这个时候就可以使用读写锁.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 package mainimport ("fmt" "sync" "time" var (int64 func write () 1 10 * time.Millisecond)func read () func main () for i := 0 ; i < 1000 ; i++ {1 )go read()for j := 0 ; j < 10 ; j++ {1 )go write()
原子操作 看的不是很懂,把gmp看完再来过一遍吧
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 var x int64 var l sync.Mutexvar wg sync.WaitGroupfunc add () func mutexAdd () func atomicAdd () 1 )func main () for i := 0 ; i < 10000 ; i++ {1 )go atomicAdd()
爬虫 爬虫步骤 明确目标(确定在哪个网站搜索)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 package mainimport ("fmt" "io" "net/http" "os" "regexp" "time" var reQQemail = `(\d+)@qq.com` func Getemail (file *os.File) "https://www.xyfinance.org/hot/516352" )"http.Get url" )defer resp.Body.Close()"io.ReadAll" )string (pagebody)-1 )for index, result := range results {0 ]1 ]"email:" , email)"QQ:" , qq)"%d. \nemail:%s\n" , index+1 , email)"QQ:%s\n" , qq)"线程用时:" , end.Sub(start))func HandleErr (err error , why string ) if err != nil {func main () "tmp/qq_email.txt" )"os.Create" )defer file.Close()
并发爬虫下载图片(速度非常慢)https://github.com/taosu0216/go_stu/tree/main/Spider
context上下文 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 package mainimport ("context" "fmt" "sync" "time" var wg sync.WaitGroupfunc worker (ctx context.Context) for {"worker" )1 * time.Second)select {case <-ctx.Done():break LOOPdefault :func main () 1 )go worker(ctx)4 * time.Second)"over" )
context.Context是一个接口,签名如下
1 2 3 4 5 6 type Context interface {bool )chan struct {}error interface {}) interface {}
Deadline方法需要返回当前Context被取消的时间,也就是完成工作的截止时间(deadline)
Done方法需要返回一个Channel,这个Channel会在当前工作完成或者上下文被取消之后关闭,多次调用Done方法会返回同一个Channel
Err方法会返回当前Context结束的原因,它只会在Done返回的Channel被关闭时才会返回非空的值
Value方法会从Context中返回键对应的值,对于同一个上下文来说,多次调用Value 并传入相同的Key会返回相同的结果,该方法仅用于传递跨API和进程间跟请求域的数据
Background()和TODO() Go内置两个函数:Background()和TODO(),这两个函数分别返回一个实现了Context接口的background和todo。我们代码中最开始都是以这两个内置的上下文对象作为最顶层的partent context,衍生出更多的子上下文对象。
Background()主要用于main函数、初始化以及测试代码中,作为Context这个树结构的最顶层的Context,也就是根Context。
TODO(),它目前还不知道具体的使用场景,如果我们不知道该使用什么Context的时候,可以使用这个。
background和todo本质上都是emptyCtx结构体类型,是一个不可取消,没有设置截止时间,没有携带任何值的Context。
With函数 此外,context包中还定义了四个With系列函数。
WithCancel 函数签名如下
1 func WithCancel (parent Context)
WithCancel返回带有新Done通道的父节点的副本。当调用返回的cancel函数或当关闭父上下文的Done通道时,将关闭返回上下文的Done通道,无论先发生什么情况。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 func gen (ctx context.Context) chan int {make (chan int )1 go func () for {select {case <-ctx.Done():return case dst <- n:return dstfunc main () defer cancel() for n := range gen(ctx) {if n == 5 {break
WithDeadline 通常是用cancel()就可以做到,但是有些时候可能会因为各种原因没有调用cancel(),这里的WithDeadline就是在cancel()出意外没有调用时的保底手段
1 func WithDeadline (parent Context, deadline time.Time)
设置dead时间,并返回一个新的上下文对象,这个新的上下文对象是对原来的上下文对象的复制,但是多了生效时间,后面再给函数传参时就可以传递这个新的对象而不是原来的对象
WithTimeOut 跟上面差不多,但timeout是隔多长时间后自动停止,设置的是一个最大时间,而前面的deadline则是具体的时间点,是绝对时间
WithValue 函数签名如下
1 func WithValue (parent Context, key, val interface {})
反射 这篇讲的挺细的https://juejin.cn/post/6844903559335526407?searchId=202310120916499405104F20617909405F
reflect包封装了反射相关的方法
反射获取interface值信息 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 package mainimport ("fmt" "reflect" func main () 123.456 func reflect_value (x interface {}) "%T\n" , v)"%T\n" , k)switch k {case reflect.Int:"是" , v.Int())default :"不是" ,v.Float())
反射获取interface类型信息 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 package mainimport ("fmt" "reflect" func main () 23.45 func re (x interface {}) "x的类型是:" , value)switch k {case reflect.Float64:"x的类型是" , k)default :"不是float64" )
反射修改值信息 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 package mainimport ("fmt" "reflect" func main () 3.14 "一开始的x:" , x)"修改后的x:" , x)func re (x interface {}) "类型是:%T,值是:%v\n" , v, v)switch k {case reflect.Float64:567.89 )"case 1 is " , v)case reflect.Ptr:12.3 )"case 2 is " , v)
查看类型、字段和方法 很乱,看的头晕,以后再学
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 package mainimport ("fmt" "reflect" type User struct {int string int func (u User) "hello" )func main () 1 ,"小明" ,18 ,func Poni (u interface {}) "类型为: " , ty)"字符串类型: " , ty.Name())"reflect.ValueOf(u) = " , value)for i := 0 ; i < ty.NumField(); i++ {"value.Field(i) = " , v)"%s : %v\n" , v.Name, v.Type)"value.Field(i).Interface() = " , val)"----------------------方法---------------------" )for i := 0 ; i < ty.NumMethod(); i++ {"m.Name: " , m.Name, " m.Type: " , m.Type)